
This time ocr.jpg is given. It’s a book.
The HTML title is also ocr.
There is an interesting sentence though, which says recognize the characters. maybe they are in the book, but MAYBE they are in the page source.

I think the pun was on the page of a book and the page source of a website …
Looking at the page source there is an HTML comment that says <!-- find rare characters in the mess below: -->.
There’s a whole bunch of a crap but when using ctrl+f to see if there are any alphabets in the mess you can see that there’s the alphabet a in the mess.
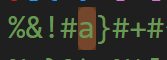
The next logical step would be to check if there are characters other than a.
You should check if there is a b, c … etc so basically the alphabet.
IMO there are 2 ways to solve this.
The first option would be to save the mess into a text file and use bash commands to extract only the alphabets.
The latter would send a request to the pythonchallenge website and filter only the alphabets.
I find the bash solution to be more simpler and easier.
1. Bash solution
Save the mess into a file and the use grep to grab only the alphabets.
cat mess | grep -o [a-zA-Z]
However the letters are separated by a newline.
e
q
u
a
l
i
t
y
tr allows you to get rid of '\n' which gives you the answer equality.
cat mess | grep -o [a-zA-Z] | tr -d '\n'
You won’t get the answer if you don’t use the brackets ([]) in the bash command. The brackets represent a range.
Sad thing is I’m not sure when you have to use ([]) and when it’s okay to not use it.
To understand those nuances you probably have to study regex as a discrete subject deeply.
I’ll try to add a better explanation if I reach that level of prowess.
I don’t think I’ll reach that level of prowess in the near future lol…
2. Using Python
import requests
import re
res = requests.get("http://www.pythonchallenge.com/pc/def/ocr.html")
boundary = r"<!--(.*?)-->"
mess = re.findall(boundary, res.text, re.DOTALL)[-1]
print(mess)
answer = "".join(re.findall(r"[a-zA-Z]", mess))
print(answer)
Using the requests module let’s you see the html page source without having to right click and inspect.
The downside of getting the page source with the requests module is that it won’t just select the mess.
It’s also selects <!-- find rare characters in the mess below: --> and <!-- our mess ...-->
Then you need to set a boundary that only selects the mess which is between <!-- -->.
When sending a request to level2 it The request just spits out <!-- find rare characters in the mess below: --> and <!-- our mess ... -->
I can use the re (regular expression) module to only select the part I want which is inside the second <!-- -->.
This is the Python code that does just what I said.
boundary = r"<!--(.*?)-->"
mess = re.findall(boundary, res.text, re.DOTALL)[-1]
using the boundary lets us narrow down the part where we need to find the alphabets.
The . in regex matches any character except a '\n'.
Our mess has a bunch of lines which means if we don’t use re.DOTALL the regex won’t get to check all the lines because the check stops if it meets a '\n'.
To prevent that from happening passing a re.DOTALL allows us to math all the lines in the mess.
The [-1] is needed because without it you can’t specify the second <!-- our mess ... --> where we need to search and gather the alphabets.
() in regex captures the pattern inside () it returns a group.
* means to match the character/group before it 0 or more.
? usually means match the character/group before it 0 or 1 times. but when used immediately after another quantifier (*, +, {m,n})
it has a different meaning.
The meaning changes from greedy to non-greedy(lazy) to match as little as possible.
Putting a r(raw-string) at the beginning doesn’t allow escaping in Python.
To wrap it up using r"" will select anything that matches that’s in between <!-- and -->
re.findall returns a list of strings that match the pattern.
To be Honest I don’t think I did a good job explaining the solution using Python. I’m not that good at regex. If you want more clear explanations you should study regex asking chatGPT, Gemini, Perplexity, Grok or any LLM will give you a better explanation with concrete examples but this is all I think I can do right now.